
When working with the HubSpot API, you may encounter an error message like this:
{
"status": "error",
"message": "You have reached your secondly limit.",
"errorType": "RATE_LIMIT",
"correlationId": "fddeaec3-849f-408a-9c15-f62281e3a285",
"policyName": "SECONDLY",
"groupName": "publicapi:crm:search:oauth:2957456:39487040"
}This means you’ve hit the rate limit for the API requests. Each HubSpot account has a defined limit of how many requests can be made per second or day depending on the account type. To avoid this issue and handle the rate limits effectively, you can implement a simple rate limiting system using backoff strategies.
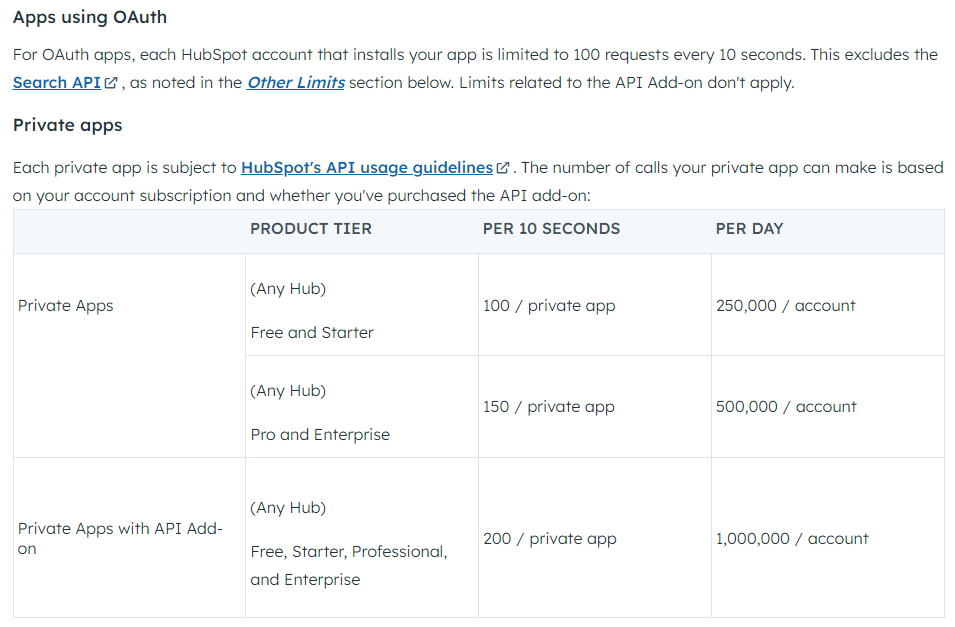
HubSpot API Rate Limits Table
See API rate limit guidelines here:
Solution Overview
We’ll create a python script that manages the rate at which your server sends API requests to HubSpot to avoid exceeding the permitted threshold. Here’s an outline of our solution:
- Track API Requests: Keep a record of API call counts within a specific time window.
- Enforce Limits: If the count exceeds the maximum allowed, wait before making new requests.
- Retry After Delay: In case of hitting the rate limit, automatically retry after a delay.
- Reset Counts: After the time window has passed or upon a successful retry, reset the request count.
Python Code Implementation
Below is the Python code snippet that demonstrates how to incorporate the rate limiter into your HubSpot client library usage.
import os
import time
# Set up HubSpot rate limiter
hubspot_api_max_limit = int(os.getenv('HUBSPOT_API_MAX_LIMIT', 3))
rate_limit_window = int(os.getenv('HUBSPOT_RATE_LIMIT_WINDOW', 10))
backoff_time = int(os.getenv('HUBSPOT_BACKOFF_TIME', 10))
api_request_count = 0
last_request_time = None
def increment_request_count():
global api_request_count
api_request_count += 1
print(f"HubSpot API request count: {api_request_count}")
def enforce_rate_limit():
global last_request_time, api_request_count
current_time = time.time()
if last_request_time is None or (current_time - last_request_time) > rate_limit_window:
reset_request_count()
last_request_time = current_time
if api_request_count >= hubspot_api_max_limit:
retry_after = backoff_time
wait_and_reset(retry_after)
else:
increment_request_count()
def get_retry_after():
return backoff_time
def wait_and_reset(retry_after):
print(f"Rate limit exceeded. Waiting for {retry_after} seconds.")
time.sleep(retry_after)
reset_request_count()
def reset_request_count():
global api_request_count
api_request_count = 0
def handle_rate_limit_error(retry_after=None):
if retry_after is None:
retry_after = get_retry_after()
print(f"Handling rate limit error. Waiting for {retry_after} seconds.")
time.sleep(retry_after)
reset_request_count()
def lambda_handler(event, _):
try:
# Place your logic code here
# Example API call enforcement
enforce_rate_limit()
# Continue with your other logic...
except Exception as outer_exception:
if hasattr(outer_exception, 'status') and outer_exception.status == 429:
handle_rate_limit_error()
# Possible calling function to retry logic
process_hubspot_event(_campaign_ref, _cycle_id, event_type, status)
else:
print(f"Error when processing HubSpot event: {outer_exception}")
raiseIn the lambda_handler function, # Place your logic code with your specific HubSpot API interaction logic. You must include a call to enforce_rate_limit() before any HubSpot API request to ensure you do not exceed the rate limit.
Final thoughts
There are many ways of handling the API rate limit in HubSpot, but in my scenario, by incorporating this script, your application can effectively manage the rate limits enforced by HubSpot. This ensures smoother and more reliable interactions between your application and HubSpot APIs, enhancing overall stability and dependability.